오렌지3 기본 가이드가 존재합니다. 오렌지3가 처음이라면 아래 글을 확인해주세요.
https://woojin1354.tistory.com/1
오렌지3 기본 가이드
오렌지(Orange)란 ?Orange는 오픈 소스 소프트웨어로 데이터 처리, 시각화, 그리고 머신러닝을 직관적으로 적용할 수 있는 강력한 프로그램입니다. 사용자 친화적인 인터페이스를 갖추고 있어 프로
woojin1354.tistory.com
데이터 분석 및 예측 모델을 이용하여 공기질에 대한 예측을 제공하는 인공지능 예제로 학습하겠습니다
공기질에 대한 여러 데이터가 주어졌을 때, 미세먼지 값(PM10)을 추론하는 일종의 다변수 함수를 구현하고자 합니다.
1. START
KAGGLE에서 Air Pollution Measurement Information in Seoul, Korea 자료를 예시로 선정하였습니다.
Measurement_summary.csv(링크)
자료를 다운받고 새로운 워크플로우를 생성합니다.
2. 데이터 불러오기
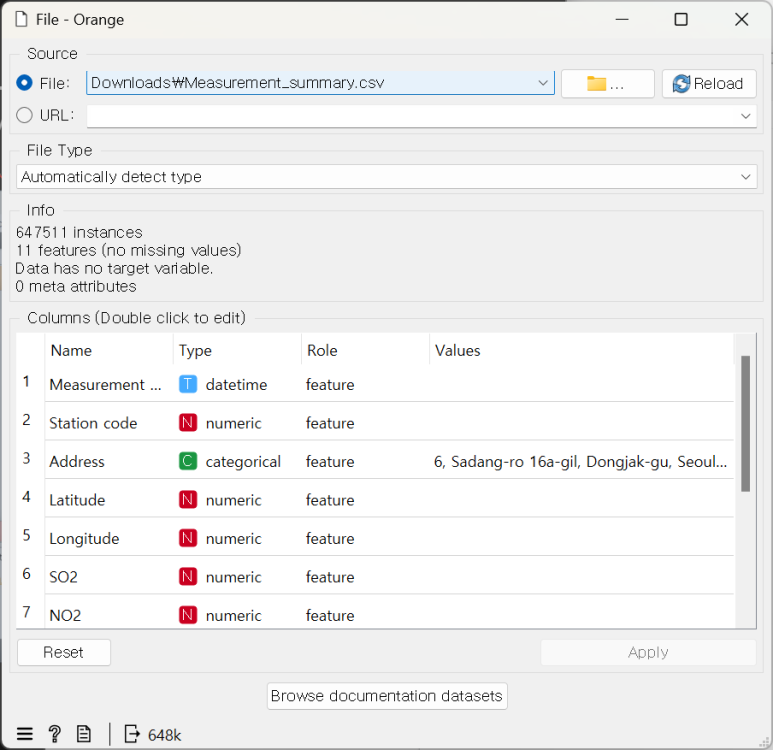
‘FILE’ 위젯을 통해 CSV 자료를 불러옵니다.
Particulate matter 10(PM10)의 Role을 target으로 변경합니다.
이는 추론 대상으로 PM10으로 선정하였다고 봐도 무방합니다.
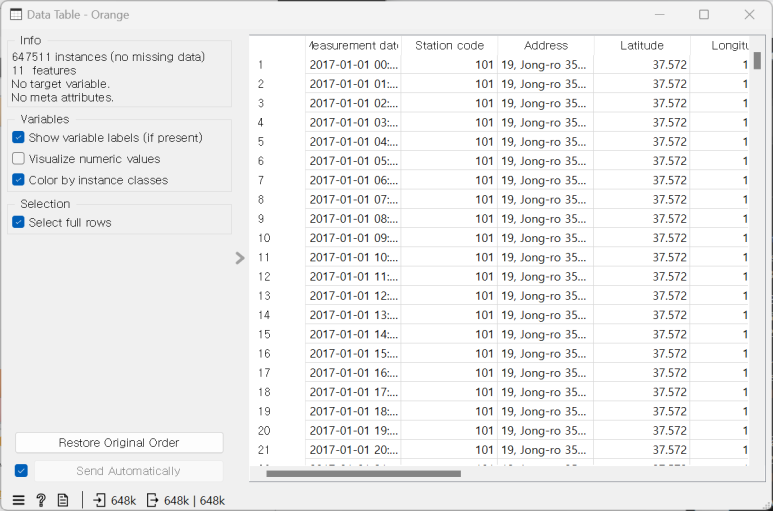
이후 DATA TABLE 위젯을 추가하여 FILE을 확인합니다
3. 선형 회귀 (LINEAR REGRESSION)
선형 회귀를 이용하여 예측 값을 생성하고 정확도를 측정하고자 합니다.
Linear Regression 위젯과 Predictions 위젯에 각각 파일을 입력해줍니다.
File 을 학습한 결과를 Predictions에 입력합니다.
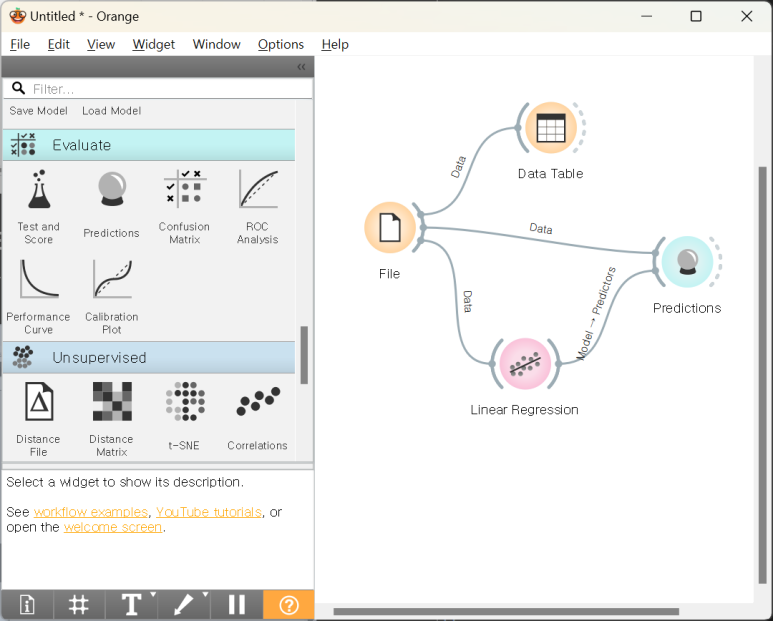
Predctions를 더블 클릭하여 결과를 확인가능합니다.
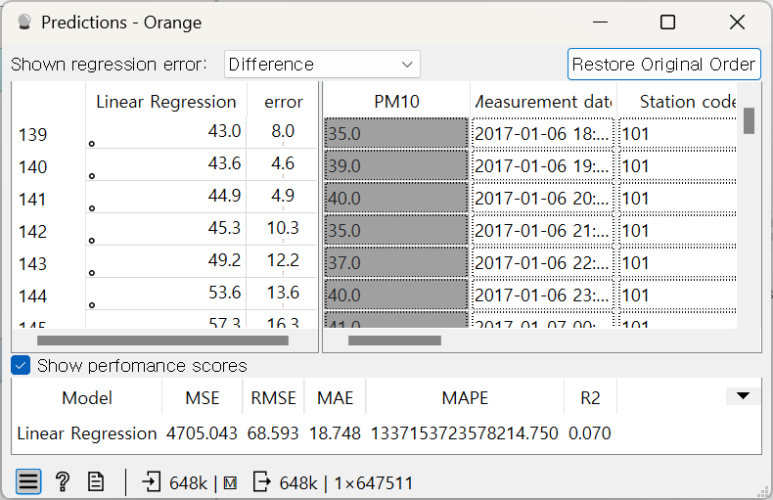
정확도면에서 다소 아쉬운 결과가 나왔습니다.
4. 더 많은 모델 추가
선형 회귀 외에도 다른 모델을 적용하고자 합니다.
인공 신경망, 랜덤 포레스트, 에이다부스트 위젯을 추가하여 File을 입력해줍니다.
결과는 Predictions로 연결해줍니다.
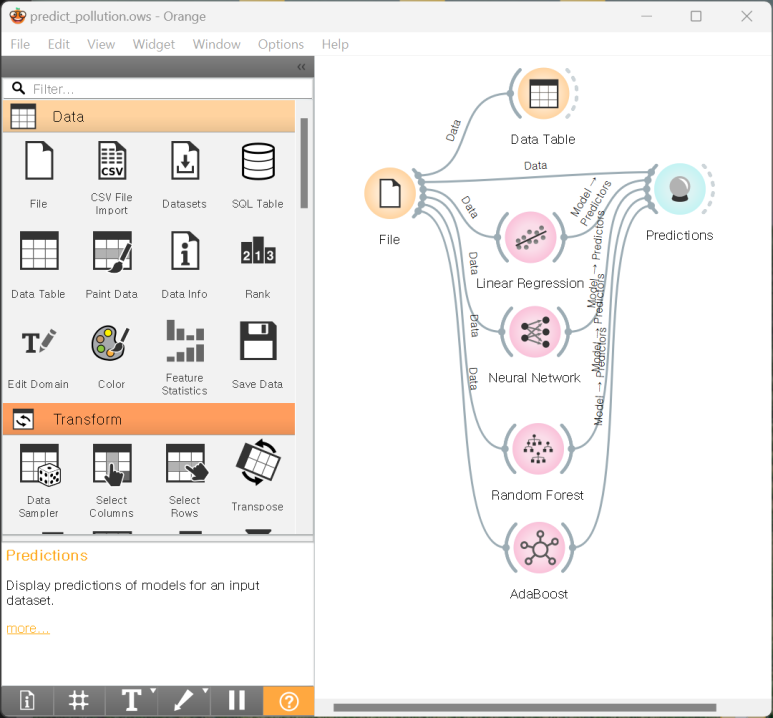
위젯을 추가하고 데이터를 입력해주면 모델이 작동하기 시작하며, 어느 정도의 시간이 소요될 수 있습니다(장치 사양에 따라 상이함)
아래는 결과입니다
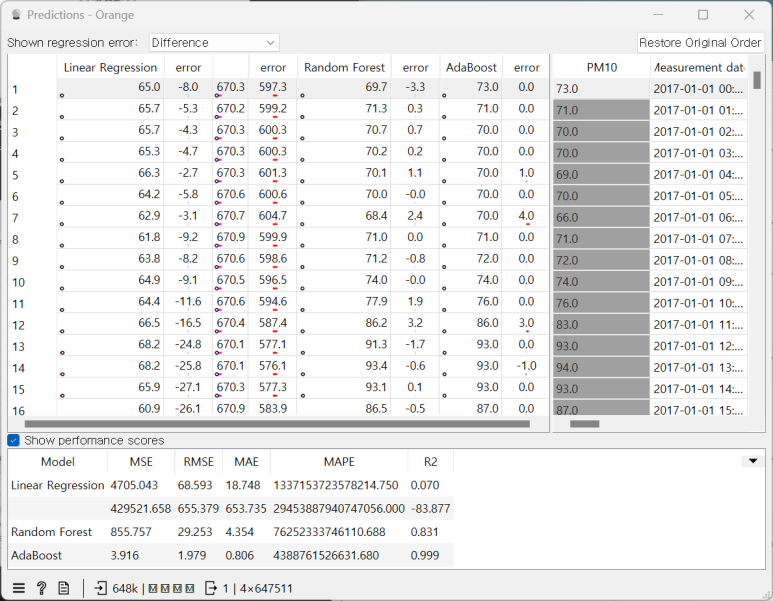
5. MSE, RMSE, MAE, R2 요약
5-1. MSE(Mean Squared Error)
예측값과 실제값 차이의 제곱 평균

특징
예측값과 실제값 차이를 제곱하기에 이상치에 민감하다.
어떤 예측이 크게 빗나가는 경우, 오차값에 크게 적용된다.
모든 함수값이 미분 가능하여 변화율 계산이 가능하다
0에 가까울수록 좋다
5-2. RMSE(Root Mean Squared Error)
MSE에서 루트를 취한 값
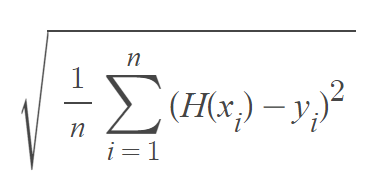
루트를 취하기에 미분 불가능한 지점을 갖게 된다
대신, 오차값에 대한 민감도가 MSE에 비해 낮다
0에 가까울수록 좋다
5-3. MAE(Mean Absolute Error)
실제 정답값과 예측값 차이를 절댓값으로 변환한 뒤 합산하여 평균을 구한다
이상치에 둔감한 편인 값이다
0에 가까울수록 좋다
5-4. MAPE(Mean Absolute Percentage Error)
평균 절대 비율 오차
MAE를 비율, 퍼센트로 표현하여 스케일 의존적 에러 문제점을 개선한다.
0에 가까울수록 좋다
5-5. R2(R Squared, R^2, 결정 계수)
실제값의 분산 대비 예측값의 분산 비율을 의미하며 1에 가까울 수록 좋다.
R2는 상대적 성능을 나타내기에 비교에 적절하다
6. 결과 분석
MSE, RMSE, MAE, R2 값을 통해 성능을 평가해보겠습니다
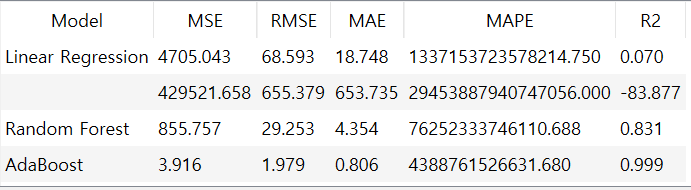
MSE, RMSE, MAE, MAPE, R2 값 모두 AdaBoost가 좋은 결과를 냈습니다
하지만 이는 AdaBoost가 현재 상황에 좋은 모델이라는 것을 증명하지는 못합니다.
7. TRAIN DATA, TEST DATA
위 결과는 Train Data와 Test Data가 일치한 상황에서 나온 결과이기에 신뢰하기 어렵습니다.
문제 은행을 보며 내용을 외운 학생의 실력이 더 뛰어나다고 보장할 수 없는 것과 같습니다
Train Data와 Test Data를 분리해보겠습니다.
‘Test and Score’ 위젯을 추가하고 AdaBoost의 출력과 File을 입력부에 연결합니다.
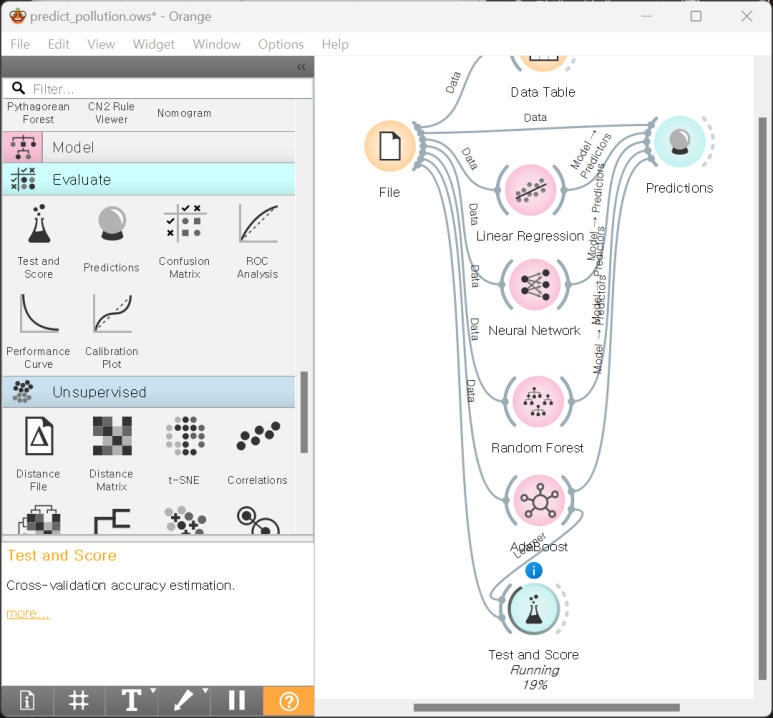
Train/Test 반복 횟수를 설정하고, Train set size 또한 설정해줍니다.
예를 들어 50%로 설정하면, 주어진 데이터의 50%는 학습에 사용하고 나머지 50%는 Test에 사용합니다. 이를 10번 반복합니다.
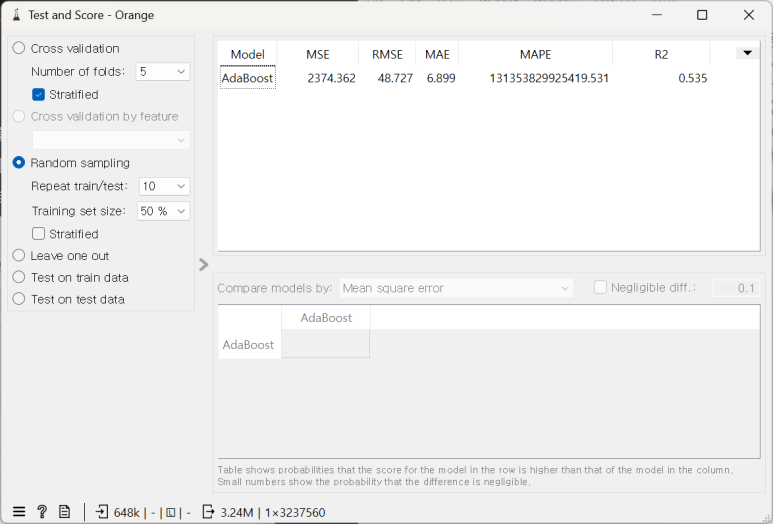
학습이 완료되면 값을 확인합니다. 이전에 확인했던 결과와는 다르게 오차 수치가 증가한 것을 확인 가능합니다
8. 인공 신경망, 랜덤 포레스트, 에이다부스트, 선형 회귀
8-1. 인공 신경망 (Artificial Neural Networks, ANN)
개념: 인공 신경망은 뇌의 뉴런과 유사한 구조를 모방한 알고리즘으로, 여러 계층(layer)으로 구성되어 데이터를 처리합니다.
특징
비선형 문제 해결: 복잡한 비선형 관계를 모델링할 수 있습니다.
표현력: 여러 은닉층(hidden layer)을 통해 고차원 데이터를 효과적으로 학습할 수 있습니다.
확장성: 이미지, 음성 인식 등 다양한 분야에서 사용됩니다.
단점
컴퓨팅 비용: 훈련에 많은 계산 자원이 필요합니다.
과적합: 복잡한 모델이 과적합(overfitting)될 가능성이 있습니다.
해석성: 모델의 내부 작동 원리를 이해하기 어렵습니다.
8-2. 랜덤 포레스트 (Random Forest)
개념: 랜덤 포레스트는 여러 개의 결정 트리(decision tree)를 앙상블하여 예측 성능을 향상시키는 알고리즘입니다.
특징
강건성: 개별 트리의 과적합을 줄여줍니다.
특성 중요도: 각 특성(feature)의 중요도를 쉽게 파악할 수 있습니다.
다양성: 분류(Classification)와 회귀(Regression) 문제 모두에 사용 가능합니다.
단점
훈련 시간: 많은 트리를 훈련시키기 때문에 시간이 오래 걸릴 수 있습니다.
메모리 사용: 많은 트리를 저장해야 하므로 메모리 사용량이 많습니다.
해석성: 개별 트리보다 모델의 해석이 어려울 수 있습니다.
8-3. 에이다부스트 (AdaBoost)
개념: 에이다부스트는 약한 학습기(weak learner)를 결합하여 강한 학습기(strong learner)를 만드는 부스팅(Boosting) 기법의 일종입니다.
특징
순차적 학습: 이전 모델의 오류를 보완하며 학습합니다.
가중치 조정: 잘못 분류된 데이터에 가중치를 부여하여 다음 모델에서 더 잘 학습하도록 유도합니다.
해석성: 비교적 간단한 모델로 해석이 용이합니다.
단점
노이즈 민감성: 노이즈 데이터에 민감하여 과적합될 수 있습니다.
병렬 처리 어려움: 순차적으로 모델을 학습하므로 병렬화가 어렵습니다.
매개변수 선택: 최적의 학습기와 매개변수 선택이 중요합니다.
8-4. 선형 회귀 (Linear Regression)
개념: 선형 회귀는 종속 변수와 하나 이상의 독립 변수 사이의 선형 관계를 모델링하는 회귀 기법입니다.
특징
간단함: 이해하고 구현하기 쉬운 모델입니다.
해석성: 결과를 해석하고 설명하기 용이합니다.
속도: 훈련과 예측이 빠릅니다.
단점
선형성 가정: 데이터가 선형 관계를 가질 때만 잘 작동합니다.
과적합: 다중 공선성(multi-collinearity) 문제로 인해 과적합될 수 있습니다.
다양한 데이터 제한: 비선형 데이터나 복잡한 관계를 잘 처리하지 못합니다.
8-5. 요약
인공 신경망: 복잡하고 비선형적인 문제에 강하지만, 해석이 어려움.
랜덤 포레스트: 안정적이고 강력한 예측 성능을 제공하지만, 메모리와 시간이 많이 소요됨.
에이다부스트: 순차적 학습으로 높은 성능을 낼 수 있지만, 노이즈에 민감함.
선형 회귀: 단순하고 빠르며 해석이 쉬우나, 데이터가 선형 관계를 가져야만 잘 작동함.
9. 에이다 부스트가 가장 높은 성능을 보인 이유
에이다부스트는 여러 개의 약한 학습기(weak learner)를 순차적으로 학습시키며, 각 학습기마다 이전 학습기에서 잘못 예측된 샘플에 가중치를 더 높게 부여하여 다음 학습기가 이를 더 잘 학습하도록 합니다. 이러한 과정은 학습 데이터에서의 오류를 점진적으로 줄여가면서 최종 모델을 강화합니다.
에이다부스트는 학습 데이터를 잘 맞추기 위해 반복적으로 모델을 개선합니다. 학습 데이터와 테스트 데이터가 동일하면, 에이다부스트는 테스트 데이터(동시에 학습 데이터)를 정확하게 맞추기 위해 최적화되기 때문에 성능이 높게 나올 수 있습니다.
에이다부스트는 각 단계에서 오류를 최소화하는 방향으로 학습하기 때문에, 학습 데이터의 오류를 거의 완벽하게 줄이는 경향이 있습니다. 동일한 데이터셋을 테스트할 경우, 에이다부스트가 학습한 패턴과 테스트 데이터의 패턴이 일치하므로 높은 성능을 보입니다.
결론적으로 에이다 부스트는 학습 데이터에 의한 과적합이 일어날 수 있기에 학습 데이터와 테스트 데이터가 동일한 경우 높은 성능을 보입니다. 그리고 이는 에이다 부스트가 뛰어난 모델이기에 나타나는 성적이 아님을 알 수 있습니다.
해당 자료의 저작권은 블로그 작성자에게 있습니다. 수업 자료로 사용하는 경우 해당 페이지를 그대로 사용하시고, 무단으로 수정 또는 복제를 금합니다.
'인공지능 · 데이터 과학 > 오렌지3' 카테고리의 다른 글
| 오렌지3 - 4화 주식 가격 예측 (0) | 2024.08.08 |
|---|---|
| 오렌지3 - 3화 이미지 분류 (0) | 2024.08.06 |
| 오렌지3 - 1화 기본 가이드 (0) | 2024.08.05 |


